-
주식 정보 데이터 수집하기 및 확인주식정보 수집하기 2021. 12. 5. 23:27
저번과 동일한 방법으로 주식정보 데이터를 수집 할 것이다. 사전 연습단계엿으니 한단계올려서 해보도록 했다. 대신 이번 데이터는 기존 KRX에서 수집한 데이터를 이용해 10년치 데이터를 수집하였다. 수집 방법은 아래 링크를 확인하자
1. 라이브러리 및 데이터 불러오기
import pandas as pd import time from pykrx import stock stock_list = pd.read_csv("stock_list.csv") stock_total = pd.read_csv("stock_list.csv") stock_total
2. 날짜 설정해주기
2011/12/01 ~ 2021/12/01 이렇게 10년을 설정해주고 주식 데이터를 수집하였다.
start_day = "20111201" end_day = "20211201"3. 반복문을 사용하여 데이터 수집
저번과 동일하게 반복문을 이용하여 데이터 수집을 해주도록 하자. pykrx 라이브러리의 get_market_ohlcv_by_date() 함수를 사용해 주식 정보를 불러오자.
stock_df_total = pd.DataFrame() for i in range(len(stock_total)): stock_code = stock_total['종목코드'][i] stock_name = stock_total['종목명'][i] market = stock_total['시장구분'][i] #stock.get_market_ohlcv_by_date 주식데이터 시작일,종료일,티커 파라미터를 넣어주면 일자별로 정렬하여 DataFrame으로 반환한다. stock_df = stock.get_market_ohlcv_by_date(fromdate=start_day, todate=end_day, ticker=stock_code) # 위 데이터를 가져오면 날짜,시가,고가,저가,..등만 나오므로 칼럼을 추가해주도록 하자. stock_df["종목명"] = stock_name stock_df["종목코드"] = stock_code stock_df["시장구분"] = market time.sleep(0.5) # time.sleep(1) 0.5초마다 데이터 실행 (데이터가 많으면 한꺼번에 처리하려해 서버 팅길수 있으므로 설정 ) print(str(i) + " 번째 "+ stock_name) # 잘 실행되는지 확인하기위해 설정 해주었다. # pd.concat 데이터 프레임 이어 붙히기 stock_df_total = pd.concat([stock_df_total,stock_df])
4. 데이터 확인
데이터를 확인해보면 알겠지만 10년치 데이터라 500만이 넘어가는 것을 볼 수 있다.
stock_df_total
5. 인덱스 제거
stock_df_total =stock_df_total.reset_index() stock_df_total
6. CSV 저장
stock_df_total.to_csv("stock_df_total.csv", index = False)7. 데이터 전처리 및 확인
나는 혹시 몰라 csv파일을 새로운 파일을 만들어 열어 주었다. 새로운 파일에서 비교하며 잘 수집 되었는지 확인해보자
7-1 라이브러리 및 데이터 불러오기
import pandas as pd stock_df_total = pd.read_csv("stock_df_total.csv")
7-2 주식정보 전처리drop_duplicates() 함수를 이용해 중복된 값은 제거 및 인덱스 재설정
df = stock_df_total[["종목명","시장구분"]].drop_duplicates() df = df.reset_index(drop =True) df
7-3 시장구분 확인하기
df.groupby(["시장구분"]).count()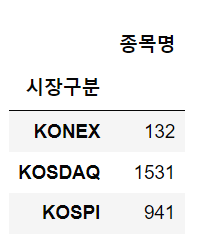
7-4 이전 데이터와 비교하기
위 데이터와 같은걸 볼 수 있다. 하지만 정확하게는 모르니 좀더 확인해 보도록하자.
stock_list.groupby(["시장구분"]).count()
7-5 sort_values() 함수 이용 정리 및 비교
df_1 = df[['종목명']].sort_values(by=['종목명'], axis=0) stock_list_1 = stock_list[['종목명']].sort_values(by=['종목명'], axis=0)
7-6 이제 두 자료를 확인해보자.
stock_check = df_1 == stock_list_1 sum(stock_check['종목명'])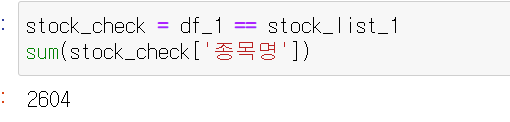
다른거 없이 2604개의 rows가 같은것을 볼 수 있다. 주식 정보를 좀금더 자세하게 파고 들어서 중간중간 회사가 없어지기도 하고 새로 생기기도 했을 것이다 다른 이유도 많이 있겠지만 그 다음 단계는 좀더 공부해서 자세하게 올려보도록 하겠다. 이 많은 데이터를 한번에 하기에는 너무 오래 걸리므로 다른 방법도 알아보고 올려보도록 하자.
'주식정보 수집하기' 카테고리의 다른 글
(Linux)환경 실행코드 python3로 주식 정보 수집 (0) 2021.12.06 streamlit으로 대시보드를 만들어보자. (0) 2021.12.03 주식 정보 수집을 위한 사전준비 및 연습 (0) 2021.12.02