-
streamlit으로 대시보드를 만들어보자.주식정보 수집하기 2021. 12. 3. 21:15
지난번에는 주식정보를 수집하는 것을 해보았다. 이번에는 이데이터로 대시보드를 만들어 보려한다. 사용한 라이브러리는 streamlit이고 streamlit에 자세한 정보는 다음과 같다.
Streamlit • The fastest way to build and share data apps
Streamlit is an open-source app framework for Machine Learning and Data Science teams. Create beautiful data apps in hours, not weeks. All in pure Python. All for free.
streamlit.io
자 그럼 이제 파이썬을 사용해서 streamlit을 알아보자.
1. 라이브러리
라이브러리는 다음과 같다
import pandas as pd import time from pykrx import stock import plotly.express as px import streamlit as st2. 메인 제목
메인 제목 명령어는 다음과 같다. st.title함수를 사용했고 자세한 정보는 앞서 말했듯이 위에 공식 링크를 참고하면 여러 함수 적용이 가능하다.
st.title('주식 대시보드')3. 데이터 수집
3-1. 주식 티커 설정
다음 주식 티커를 받아와 데이터 프레임을 만들어주자. 이는 반복문을 사용해서 이어붙일 예정이다.
stock_info= pd.DataFrame({ 'stock_name': ['삼성전자', "SK하이닉스", "LG전자","현대중공업"], 'stock_code': ["005930", "000660", "066570","329180"]})3-2 . 날짜 설정
날짜는 다음과 같이 2021/01/01 ~ 2021/12/01 까지 설정해 주도록 하자.
start_day = "20210101" end_day = "20211201"3-3 반복문을 사용하여 데이터 수집
이번에는 반복문을 사용해서 데이터를 수집해보자. pykrx 라이브러리의 get_market_ohlcv_by_date() 함수를 사용했으며 이 구성에 대한 자세한 정보는 지난 블로그에 있으니 다음을 참고하자
stock_df_total = pd.DataFrame() for i in range(len(stock_info)): stock_code = stock_info['stock_code'][i] stock_name = stock_info['stock_name'][i] stock_df = stock.get_market_ohlcv_by_date(fromdate=start_day, todate=end_day, ticker=stock_code) # 위 데이터를 가져오면 날짜,시가,고가,저가,..등만 나오므로 칼럼을 추가해주도록 하자. stock_df["종목명"] = stock_name stock_df["종목코드"] = stock_code time.sleep(1) # time.sleep(1) 1초마다 데이터 실행 (데이터가 많으면 한꺼번에 처리하려해 서버 팅길수 있으므로 설정 ) print(str(i) + " 번째 "+ stock_name) # 잘 실행되는지 확인하기위해 설정 해주었다. # pd.concat 데이터 프레임 이어 붙히기 stock_df_total = pd.concat([stock_df_total,stock_df]) #인덱스 제거 stock_df_total = stock_df_total.reset_index()4. 데이터 시각화
다음은 데이터를 이용하여 데이터 시각화를 해보자. 여기서 중요한 점은 plotly()함수를 사용했을때 streamlit에서는 st.plotly_chart()함수를 사용해 표현한다.
4-1. 시각화1
fig = px.line(stock_df_total, x="날짜", y="종가", color='종목명') st.plotly_chart(fig, use_container_width=True)4-2 시각화2
total_df = stock_df_total.pivot(index='날짜', columns='종목명', values='종가') fig2 = px.area(total_df, facet_col="종목명", facet_col_wrap=2) st.plotly_chart(fig2, use_container_width=True)5. streamlit 실행
이번에는 위의 코드로 이루어진 파이썬 파일을 실행해보자. streamlit의 실행코드는 다음과 같다. 이렇게 실행해서 (IP주소):8501 을 URL에 실행했을때 성공적으로 대시보드를 볼 수 있다.
$ streamlit run {파일명}.py 2021-12-03 11:49:34.128 INFO numexpr.utils: NumExpr defaulting to 2 threads. You can now view your Streamlit app in your browser. Network URL: http://{IP주소}:8501 External URL: http://{IP주소}:85016. 최종 결과
이렇게 구동한 결과는 다음과 같다.
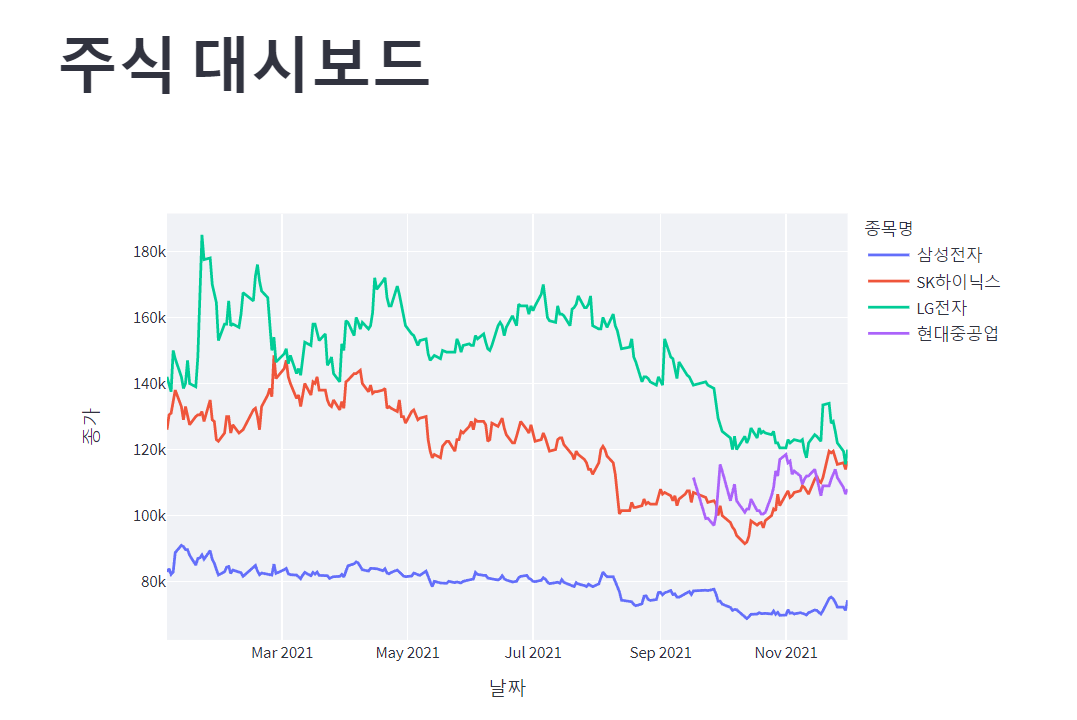
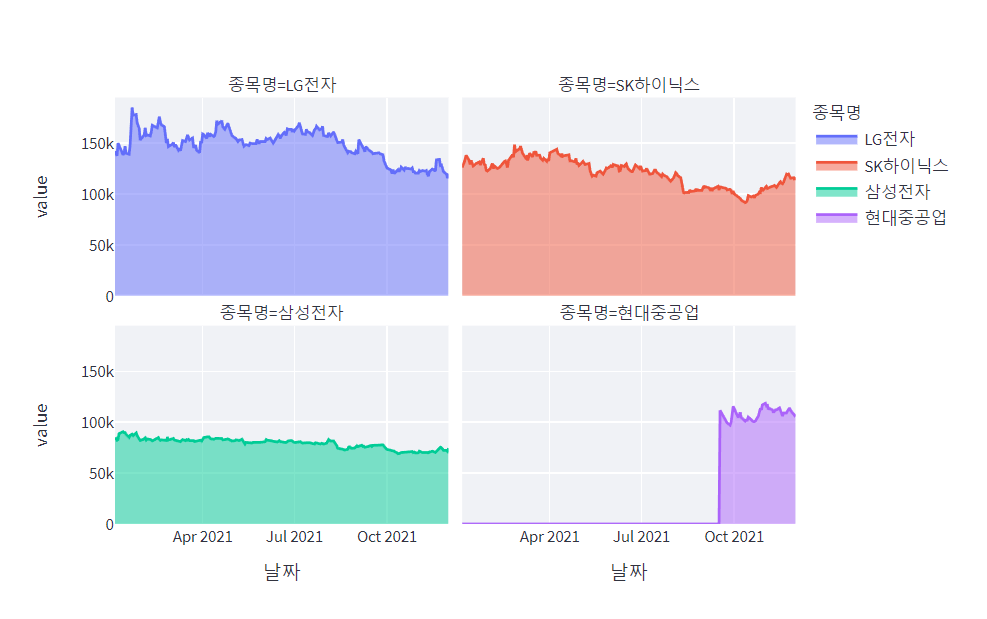
'주식정보 수집하기' 카테고리의 다른 글
(Linux)환경 실행코드 python3로 주식 정보 수집 (0) 2021.12.06 주식 정보 데이터 수집하기 및 확인 (0) 2021.12.05 주식 정보 수집을 위한 사전준비 및 연습 (0) 2021.12.02